Lung Cancer Prediction
In this project, I developed a Deep Learning model to predict lung cancer based on various patient characteristics. Utilizing an open-license dataset, I experimented with different machine learning methods using Python.
Data Processing and Exploration
I began by thoroughly processing the data, which involved ensuring that the features (X) were independent, checking for duplicates, and analyzing the distributions and potential patterns within the data.
Model Development and Evaluation
After cleaning and preparing the data, I tested several prediction models. The performance of these models was evaluated using the
F1-Score, Recall and Precision with a confusion matrix, and 20% of the data was set aside for validation purposes.
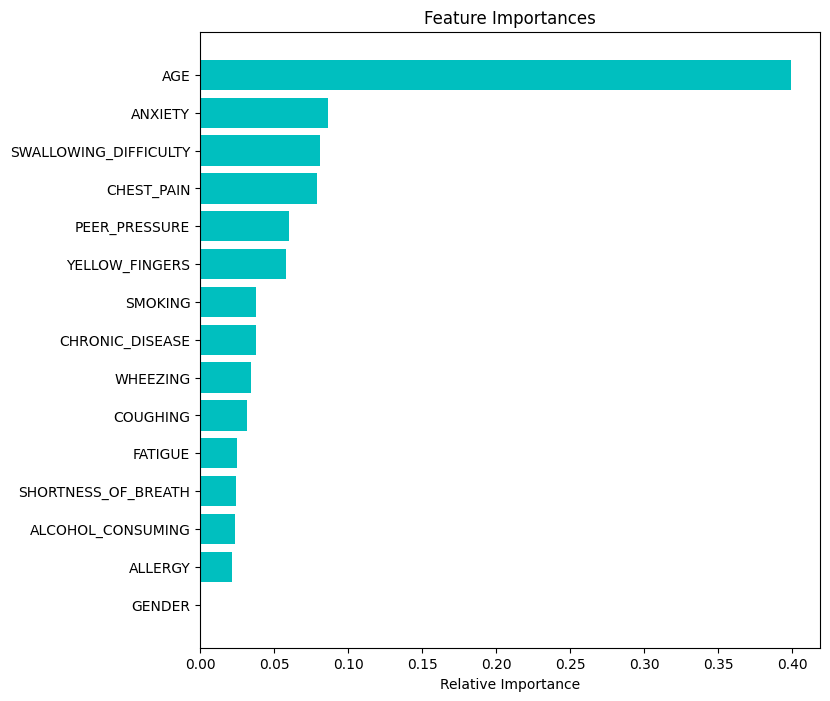
Decision Trees and Random Forests: Initially, I used simple decision trees from the scikit-learn library, tuning the hyperparameters to optimize performance. Following this, I implemented Random Forest models, also using scikit-learn. Interestingly, both models highlighted ‘age’ as the most important feature, followed by ‘anxiety’, ‘chest pain’, and ‘swallowing difficulty’. However, tuning the hyperparameters of the Random Forest did not lead to significant improvement in the model’s performance.
Deep Learning Models: To further enhance the model, I explored deep learning techniques. Using the Simple Imputer from scikit-learn, I experimented with different numbers of layers and neurons. However, these models tended to overfit the training data. I employed RandomSearch from Keras to identify the optimal number of neurons and layers. Additionally, I used RandomSearch again to determine the best parameters for applying Dropout to mitigate overfitting.
This approach resulted in the best F1 Score of 0.60, with a Recall of 0.64 and Precision of 0.55.
Key Findings
One of the most interesting findings was the importance of certain features in predicting lung cancer. Both the decision tree and random forest models identified ‘age’ as the most critical factor, followed by ‘anxiety’, ‘chest pain’, ‘wheezing’, and ‘swallowing difficulty’. This insight could be valuable for further research and improving lung cancer prediction models.
You are welcome to review the code in my GitHub repository and find a detailed breakdown of my process below.
Dataset Description
The data set has 3000 rows and 16 columns
The dataset included the following columns:
– Gender
– Age
– Smoking
– Yellow fingers
– Anxiety
– Peer pressure
– Chronic disease
– Fatigue
– Allergy
– Wheezing
– Alcohol consuming
– Coughing
– Shortness of breath
– Swallowing difficulty
– Chest pain
Libraries Used
For this project, I utilized several Python libraries to handle data processing, visualization, and modeling, including:
Pandas: For data manipulation and analysis.
Numpy: For numerical computations.
Matplotlib: For creating static, animated, and interactive visualizations.
Seaborn: For statistical data visualization.
TensorFlow & Keras: For building and training deep learning models
Scikit-learn: For machine learning algorithms and utilities.
Data Distribution and Patterns
Upon analyzing the distribution and patterns within the data, I verified if any columns had a marked pattern or a higher concentration of positive lung cancer cases but found no clear pattern. The gender distribution is balanced with a 50-50 split between males and females. The ages of the patients range from 30 to 80, with 21% of the patients falling in the 30-39 age group. Additionally, the distribution of positive lung cancer cases among genders is nearly balanced, close to a 50-50 split. The only notable imbalance is that a higher percentage of patients aged 30-39 tested positive for lung cancer.
Decision Tree Classifier
After ensuring that the independent variables did not show correlation, which could be problematic for the models, I scaled the age data and encoded gender as 0 and 1. I started with the DecisionTreeClassifier.
The initial Decision Tree classifier showed overfitting with the training data and produced moderate performance with an F1-Score of 0.52.
| Precision | recall | f1-Score |
|---|---|---|
| 0.47 | 0.52 | 0.52 |
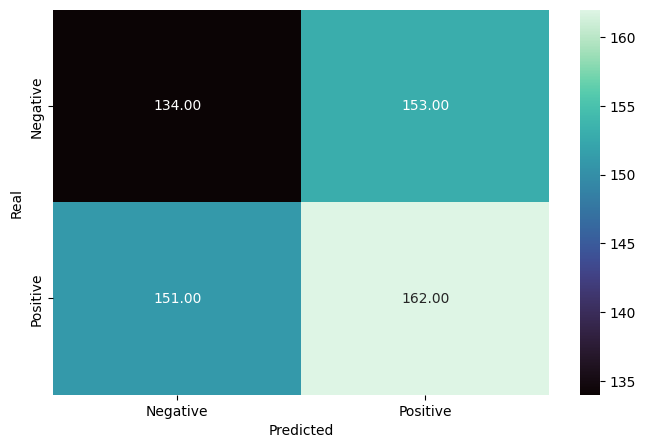
After hyperparameter tuning, the performance slightly improved but was not significantly better, with an F1-Score of 0.53.
| Precision | recall | f1-Score |
|---|---|---|
| 0.50 | 0.53 | 0.54 |
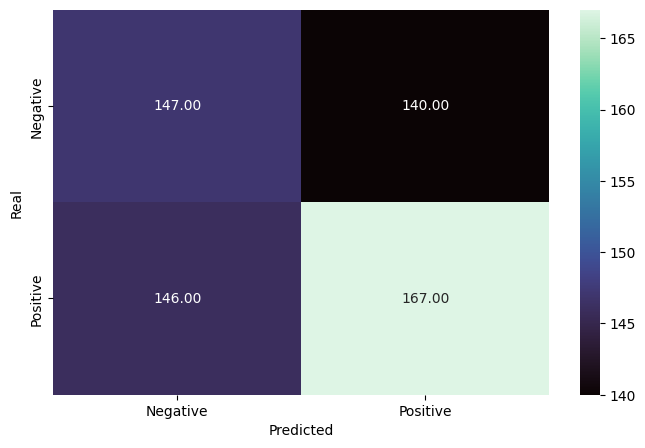
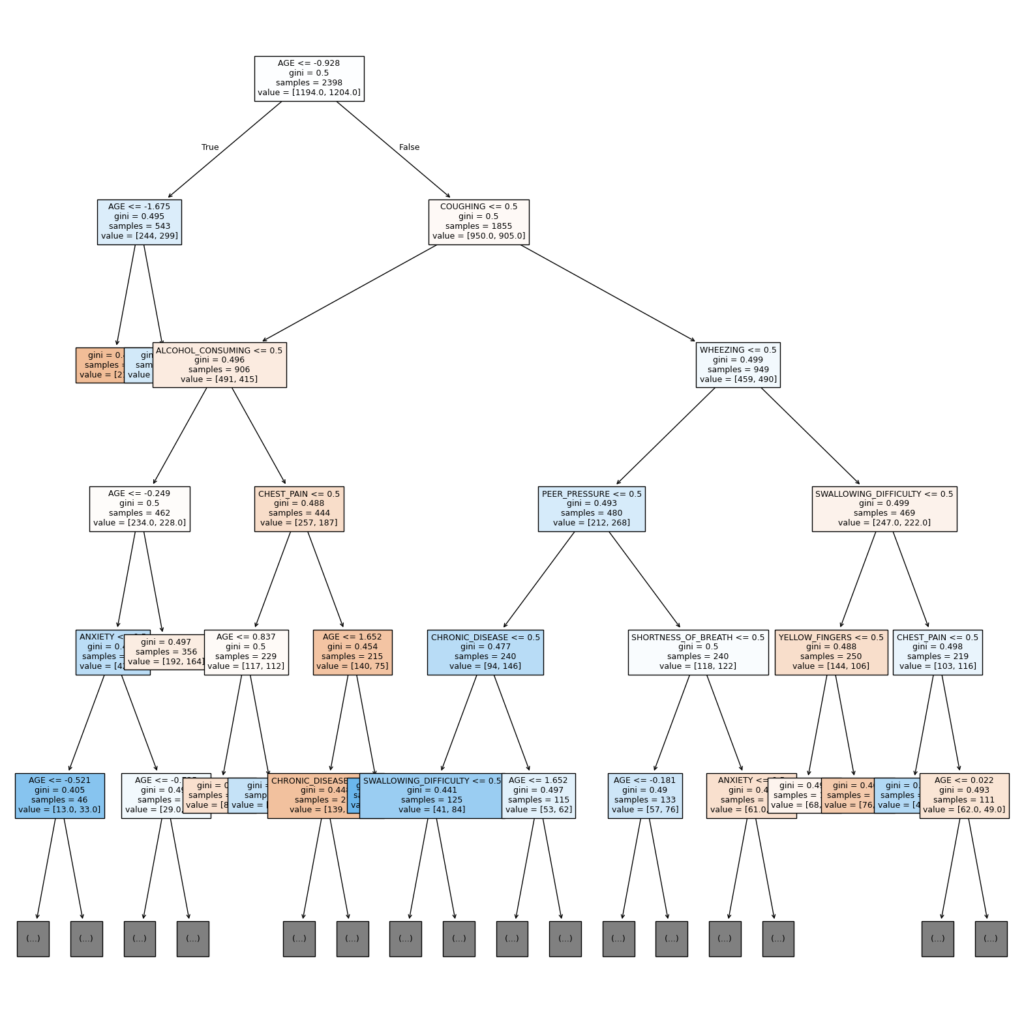
Here is a brief representation of the first layers of the decision tree. It starts with the condition of age being greater than -0.928 (due to the scaling, which corresponds to 40 years).
This is followed by another age check and whether the patient has coughing symptoms.
Below is a table showing the feature importances.
Random Forest
I then proceeded with the Random Forest method. The initial Random Forest model also overfitted and provided a normal prediction result with an F1-Score of 0.53.
| Precision | recall | f1-Score |
|---|---|---|
| 0.50 | 0.51 | 0.53 |

After hyperparameter tuning, the performance of the Random Forest improved. It no longer overfitted and provided a higher F1-Score than the tuned Decision Tree, with an F1-Score of 0.56.
| Precision | recall | f1-Score |
|---|---|---|
| 0.52 | 0.56 | 0.56 |
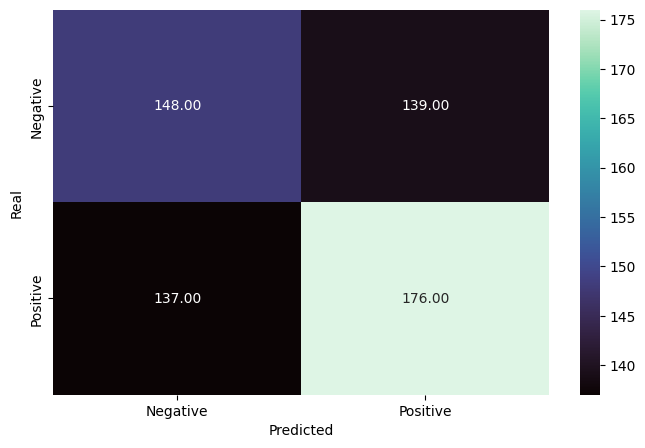
Deep Learning Models
Not satisfied with the performance, I decided to explore deep learning models using SimpleImputer from Scikit-Learn. I tested different configurations with multiple parameters, EarlyStopping, Dask and SMOTE to create new, synthetic observations from present samples, but the method that worked best was DropOut. Along with RandomSearch from Keras-Tuner, I found a good number of neurons and layers for the model. After another round of RandomSearch, I optimized the hyperparameters for neuron DropOut. Here is my final model:
model = Sequential()
model.add(Dense(192,activation='relu',kernel_initializer='he_uniform',input_dim = X_train.shape[1]))
model.add(Dropout(0.35))
model.add(Dense(64,activation='relu',kernel_initializer='he_uniform'))
model.add(Dropout(0.25))
model.add(Dense(224,activation='relu',kernel_initializer='he_uniform'))
model.add(Dropout(0.35))
model.add(Dense(32,activation='relu',kernel_initializer='he_uniform'))
model.add(Dropout(0.1))
model.add(Dense(32,activation='relu',kernel_initializer='he_uniform'))
model.add(Dense(1, activation = 'sigmoid'))

| Precision | recall | f1-Score |
|---|---|---|
| 0.55 | 0.64 | 0.60 |
Finally, the deep learning model with 6 layers achieved an F1-Score of 0.60. With a larger dataset, the performance could have been better, but I am happy with the result. I welcome any feedback and constructive criticism. Thank you.
Sergio Lezama – info@sergiolezama.com